
Retrieval-Augmented Generation (RAG) is a powerful technique that combines Large Language Models (LLMs) with external retrieval systems to generate more accurate, contextually relevant, and dynamic responses. In essence, RAG adds a retrieval step to your model’s pipeline, enabling it to query databases or knowledge bases in real-time, ensuring that the generated output remains up-to-date and enriched with the latest information.
By retrieving the most relevant context from external sources, an LLM can produce responses that far exceed the limitations of its inherent training data. This results in more factually accurate, grounded, and context-sensitive outputs.
Why Use RAG to Improve LLMs?
- Enhanced Accuracy and Relevance: By pulling in real-time data from a knowledge base, search index, or other external databases, RAG reduces the likelihood of hallucinations or outdated information.
- Reduced Hallucinations: Because the model relies on specific context from retrieval, it is less prone to generating baseless or made-up responses.
- Scalability: You can dynamically scale the knowledge base or data source, which means you do not have to retrain or fine-tune the entire model when new information is added.
- Efficient Memory Use: Instead of forcing the model to memorize vast amounts of domain-specific knowledge, retrieval allows for on-demand context loading, optimizing memory usage.
Additional Benefits
- Dynamic Personalization: When dealing with personalized content (e.g., customer history or preferences), RAG can instantly fetch relevant data, leading to more tailored and satisfying user interactions.
- Improved Compliance: Organizations with strict regulations (finance, healthcare, etc.) can maintain a single source of truth for compliance-related information. RAG ensures the model references compliant data in real-time.
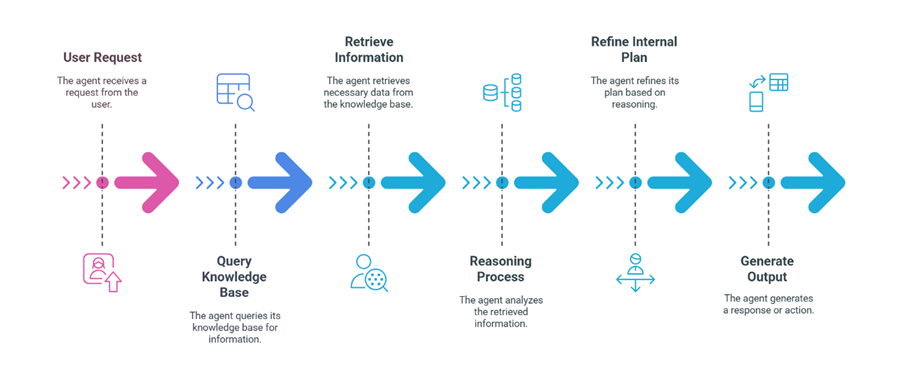
Steps to Implement a RAG Pipeline
Now that we’ve seen the core benefits of using RAG, let’s transition to a practical overview of how to set up a RAG pipeline step by step.
- Document Ingestion: Gather and organize your data in a structured or semi-structured form. This could be PDF manuals, blog posts, or product catalogs. Proper classification and tagging will help retrieval systems surface the right content.
- Indexing and Retrieval: Use neural search or other vector-based indexes to store and retrieve the most relevant text snippets. This involves generating embeddings for each document or section, allowing the system to compare similarity scores.
- Context Embedding: Convert both the query and your documents into embeddings for efficient similarity matching. This is crucial for linking user queries to the most pertinent resources.
- Response Generation: Pass the retrieved documents as context to the LLM, prompting it to generate a precise and context-informed answer. This step is where the synergy between retrieval and generation truly shines.
- Post-Processing: Filter or refine the output to ensure it meets quality, factuality, or policy standards. This might involve rule-based checks, additional AI models, or human review for sensitive applications.
Best Practices for Implementation
- Monitoring & Logging: Keep track of retrieval success rates and user feedback to fine-tune your indexing strategies.
- Regular Data Updates: Maintain an up-to-date knowledge base by scheduling periodic re-indexing, especially if your data changes frequently.
- Prompt Engineering: Craft your prompts carefully to guide the LLM in using the retrieved context effectively.
RAG Use Cases
- Customer Support: Provide instant, context-based solutions by querying a knowledge base of FAQs and user guides. For example, an AI chatbot could handle tier-1 support queries by leveraging internal documentation.
- Enterprise Knowledge Management: Surface relevant internal documents to employees, streamlining workplace queries. RAG can unify disparate repositories, allowing quick access to internal reports, memos, and policies.
- Healthcare and Legal: Retrieve the latest research papers or case law to produce evidence-based recommendations. In healthcare, this can mean referencing up-to-date medical journals or treatment guidelines, while legal professionals can access case precedents.
- Educational Platforms: Offer quick, vetted answers from curated course materials. Personalized learning paths can be built by retrieving only the most relevant educational resources.
Emerging Use Cases
- Research & Development: Scientists and researchers can pull data from multiple scientific databases, ensuring they are citing the latest findings.
- Content Creation: Writers or marketing teams can gather relevant facts and stats without manual searching, leading to more efficient content generation.
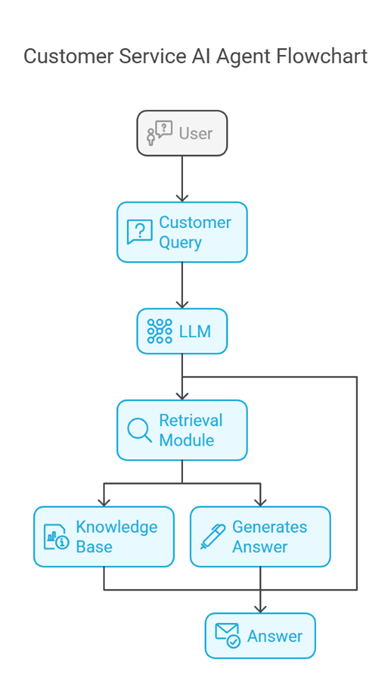
Agentic RAG
Agentic RAG involves integrating RAG-based systems with autonomous agents that can reason, plan, and act on the retrieved information. An agent might:
- Interpret user intent and decompose tasks.
- Retrieve relevant documents based on real-time context.
- Generate intermediate conclusions or actions.
- Continuously refine outputs by looping back into the retrieval system.
With Agentic RAG, these systems become proactive, autonomously updating their approach and data sources as tasks evolve. This allows for more complex workflows where the AI agent can branch off to different tasks, validate or compare data, and refine its own answers.
Practical Example of Agentic RAG
Imagine an AI project manager that oversees a multi-step product launch:
- The agent pulls current product requirements from a shared drive.
- Cross-references marketing guidelines to ensure messaging is on-brand.
- Suggests tasks to each team member.
- Continually updates the knowledge base with the latest project changes.
RAG vs. Fine-Tuning
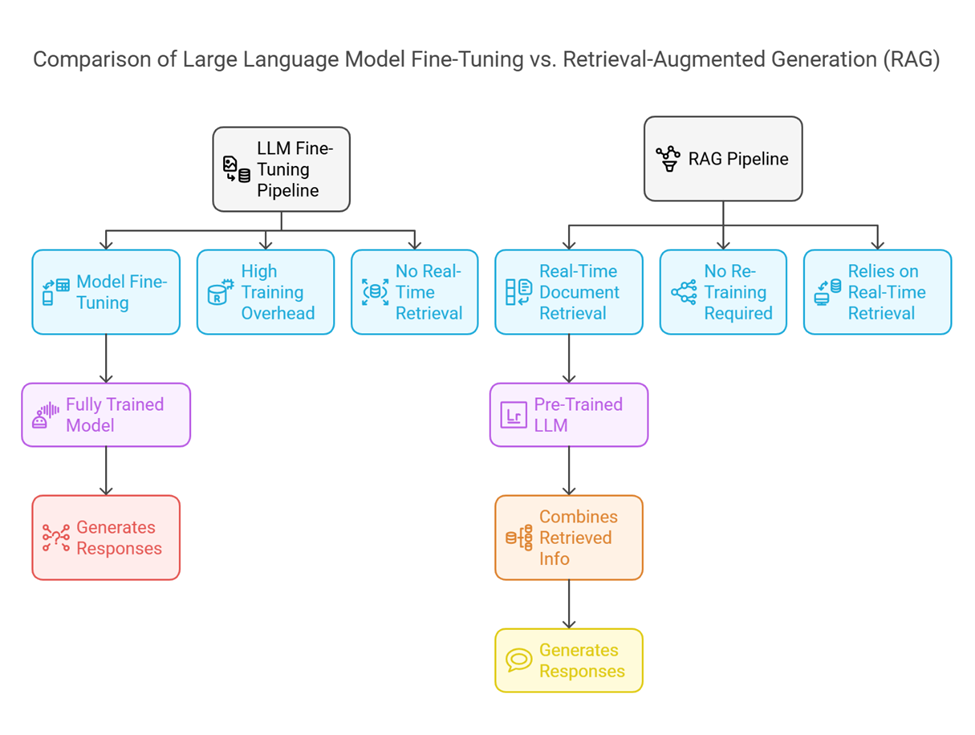
In a traditional Generative AI (GenAI) setup, a Large Language Model relies primarily on the data it was trained on. Although this approach can produce compelling text, it’s inherently limited by the model’s cut-off date and training corpus. In contrast, GenAI with RAG brings retrieval into the mix, empowering the AI to access the latest and most relevant information from external sources.
Key Differences
- Data Currency: Standard GenAI may produce answers based on outdated or incomplete training data, whereas RAG systems can fetch up-to-date information from dynamic sources.
- Accuracy and Reliability: A purely generative system can hallucinate or invent answers. RAG mitigates this risk by grounding responses in real documents.
- Memory Constraints: Standard GenAI attempts to encode vast domain knowledge into the model parameters. RAG offloads a portion of that memory requirement to an external database, improving model efficiency.
- Adaptability: GenAI with RAG can rapidly accommodate shifts in domain knowledge—like new policies, products, or scientific discoveries—without requiring an entire model retraining.
Practical Example: Imagine a travel planning chatbot. Without retrieval, it might only provide information up to the training date and might miss newly introduced travel restrictions or accommodation deals. With RAG, the bot can fetch these updates in real time from trusted sources, ensuring users receive accurate, current recommendations.
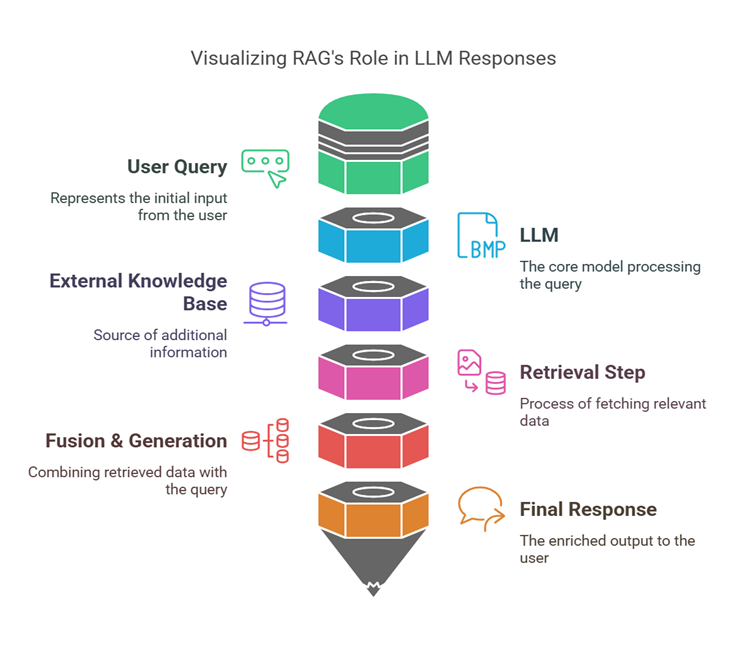
Below is a conceptual diagram illustrating how RAG integrates with your LLM to retrieve and generate. This image shows how the LLM pulls relevant data from an external knowledge base (through retrieval), combines it with the user query, and then generates a context-driven response. Look for arrows indicating how data flows and how responses get refined by external context:
Performance and Scalability Considerations
- Index Size: As your index grows, retrieval times may increase. Optimize by segmenting large documents or using hierarchical indexes.
- Latency: Combining retrieval with generation adds an extra step. Techniques such as caching frequent queries or employing faster retrieval methods (like approximate nearest neighbor search) can help.
- Cost Management: While RAG saves on continuous fine-tuning, large-scale deployments need to manage costs associated with maintaining an extensive knowledge base and performing real-time retrieval.
Final Thoughts
Retrieval-Augmented Generation (RAG) unlocks new possibilities for building intelligent applications that are both highly accurate and context-aware. By leveraging external knowledge bases, RAG systems outperform standalone models in terms of factual reliability and scalability. From customer support to enterprise search, implementing RAG can dramatically improve user experience and efficiency.
Stay tuned for more insights on how to optimize your RAG pipelines, explore advanced prompt engineering, and stay ahead in the rapidly evolving world of AI.
Leave a Reply